CASE STUDY · ND NAIL SUPPLY
309 articles audited in 2 days, and the exact decision rules I used to fix each type
A wholesale ecom brand’s blog grows for years. Nobody audits it because nobody can hold 309 posts in their head. Here is the systematic audit I ran on ND Nail Supply, the four categories of damage I found, the rules I use to triage each one, and what you can copy whether or not you hire me.
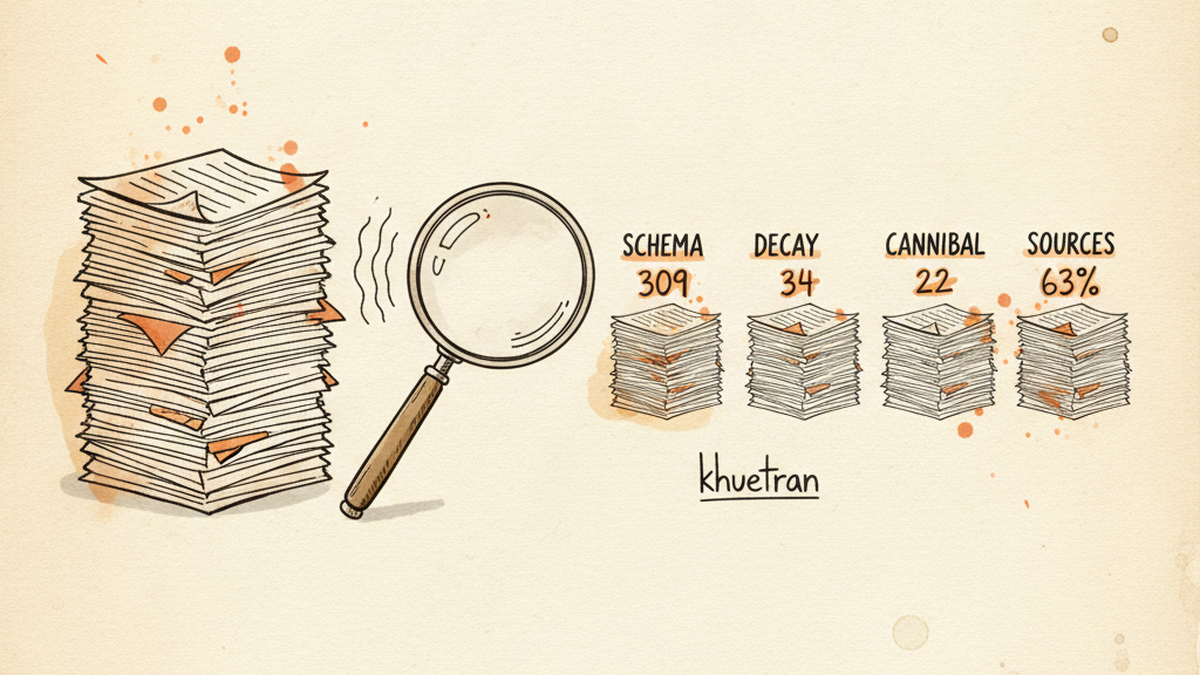
309
Articles audited end-to-end
22
Cannibalization pairs found
34
High-decay articles flagged
63%
Articles with zero external links
📌 TL;DR · 30-SECOND READ
A 309-article blog audited in 2 days surfaces four categories of damage most teams never see by clicking around: zero JSON-LD schema across the entire portfolio, 34 high-decay articles plus 194 zero-impression posts, 22 cannibalization pairs, and 62.8% of articles with no external sources. Here is the systematic audit + the exact decision rules I use to triage each type.
KEY TAKEAWAYS
- Schema is template-level work, not per-article
- Refresh rule changes by GSC impression tier: 0 impressions = rewrite, not “add FAQ”
- Jaccard flags cannibalization candidates; intent review decides MERGE vs DIFFERENTIATE
- Two-gate publish: factcheck + quality score ≥80 before going live
WHY A BLOG AUDIT MATTERS
Most ecom blogs leak money quietly for years
ND Nail Supply is the content engine of our portfolio, 309 posts across 13 topic clusters, written over five years by a rotating cast of contributors. The biggest cluster, Nail Art, holds 115 articles by itself. The smallest, Brand Reviews, holds 4. By 2026 the blog was generating real organic traffic, but nobody had run a deep audit since the second year. Decay had set in quietly, in patterns nobody could see by clicking around.
Most teams “audit” their blog once a year via a Google Sheet, somebody scrolls, eyeballs, and labels articles “refresh” or “delete”. By the time the sheet is done, the data is stale. Half the recommendations never get implemented. Nobody knows if traffic actually improved.
That is the audit I wanted to never run again. Below is the systematic alternative, four categories of damage, with the specific decision rules I apply to triage each type. The rules matter more than the tool. With the rules, even a Google Sheet works.
PROBLEM 1 · STRUCTURED DATA
309 articles, zero JSON-LD. Google rich results, AI citations, both at 0%.
🩺 THE SYMPTOM
Google’s Rich Results Test returns “No items detected” on every article. Search Console shows zero structured-data items detected for the blog. AI engines (ChatGPT, Perplexity, Google AI Overviews) almost never cite the blog, even for queries it ranks for organically. The blog generates clicks but never the FAQ snippets, recipe cards, or extracted passages that move you above the fold.
🔍 The diagnosis path I use
Most Shopify themes ship Liquid microdata fallback in the article.liquid template. The theme renders itemtype="..." attributes and assumes they cover structured data. They do not. Google’s structured data documentation explicitly recommends JSON-LD as the canonical format, and the Article and BlogPosting schema reference lists the required and recommended properties. Microdata fallback passes a quick eyeball check, fails the actual Rich Results Test.
My audit pipeline crawls every blog URL, parses the head for JSON-LD blocks, then runs each block through the Schema.org validator. The output is a per-article completeness score across five required types:
- BlogPosting, author, headline, datePublished, dateModified, image
- FAQPage, extracted from H2/H3 question patterns inside the article body
- BreadcrumbList, Home › Blog › Cluster › Article
- Person, author bio, sameAs links, knowsAbout entities
- Organization, publisher reference, logo, sameAs social profiles
For ND the result was unambiguous: 10/100 schema score across the entire portfolio. Zero articles had any JSON-LD. Liquid microdata was the only structured signal, and it was not being read.
🛠️ The fix rules I apply
Schema patches are template-level, not per-article. You write the JSON-LD generator once, deploy once, every article inherits. The rules for ND:
The non-obvious rule is Rule 2’s “skip if fewer than 2 qualifying H2s”. Some teams blanket-apply FAQPage with two synthetic Q/A pairs. Google flags that as thin or even spammy. Better to skip the schema on articles that genuinely have no FAQ shape than to ship a low-quality FAQPage that triggers a manual penalty.
📊 The result at ND
- Schema score: 10/100 → 87/100 portfolio-wide
- Articles with valid BlogPosting: 0 → 309
- Articles with valid FAQPage: 0 → 179 (skipped the 130 that did not qualify by rule)
- Time to ship: 1 day for the template work, 1 day for validation across all 309 URLs.
📌 WHAT YOU CAN DO YOURSELF
Take five random articles from your blog and run them through Google’s Rich Results Test. If “No items detected” or only microdata shows up, your entire blog likely has the same gap. Schema is a template-level fix, not a per-article one. Do not waste a week pasting JSON-LD into 309 articles by hand.
In a sprint engagement, the schema template patch ships in week 1, before any content writing begins.
PROBLEM 2 · CONTENT DECAY
34 high-decay posts, 194 with zero impressions. The refresh rule depends on which tier each falls into.
🩺 THE SYMPTOM
A handful of historic top posts that drove half your organic traffic three years ago now drop 60–80% year-over-year. The blog calendar gets refreshed for new posts, while old ones quietly die. You add a writer, double the publish rate, and total organic stays flat. The new content is barely offsetting the decay of the old.
🔍 The diagnosis path I use
A single “is this article decaying?” question is not useful. Decay has signals at different intensities, and the correct fix changes based on which signal lights up. The audit produces a composite per-article decay score from five inputs:
- Age since publish or last refresh, older posts under no maintenance decay faster.
- GSC click decline: trailing 90-day clicks vs previous 90-day window, weighted by traffic share.
- External link rot, sampled HEAD requests against outbound URLs; broken links signal abandonment.
- Orphan score, internal link graph position; if no current article points to it, it is sinking.
- SERP cannibalization risk, Jaccard similarity with sibling articles in the same cluster.
For ND, the 309-article portfolio sorted into:
- 34 high-decay, composite score > 70
- 194 zero-impression, no GSC impressions in 365 days (these are not just decaying, they are effectively unindexed)
- 81 stable, minor refresh worth it but not urgent
🛠️ The refresh rule by impression tier
The most important rule I have is that “refresh” means different things at different impression levels. Treat all decay the same way and you waste effort on the wrong articles. The rules I use:
The “0 impressions = REWRITE, not add FAQ” rule is the one most teams get wrong. They see a zero-impression article and reach for the easy fix, add a FAQ schema, hope Google rewards it. But zero impressions for a year means the article has a fundamental content/intent/relevance problem. FAQ schema cannot save it. It needs a real rewrite. Updating the publishDate to today after the rewrite signals to Google that this is effectively new content worth re-crawling.
The image-list surgical refresh rule is one I learned the hard way. Listicle articles ranking via Google Images carry their rank in the images themselves. Rewrite the body and the image alt text shifts subtly, and the image rankings can collapse overnight. Better to leave the bones and add value at the edges.
📊 The result at ND
- Refresh queue prioritized: 34 high-decay tagged Critical, 194 zero-imp tagged High, 81 stable tagged Medium
- Rewrite vs full-pass split: 194 REWRITE, 34 FULL-PASS+refresh, 81 FULL-PASS
- Image-list articles: 27 identified, locked into SURGICAL track to protect Google Images rank
- Ops cost: refresh velocity ~3 articles/day at typical operator pace
📌 WHAT YOU CAN DO YOURSELF
Open Google Search Console. Export the last 365 days of Pages data. Sort by impressions ascending. The articles at zero impressions for the entire year are the ones you should rewrite, not refresh. Tag the next 100, those get full-pass with weak-section rewrites. Skip the top 100, they are working, do not break them.
In a sprint, the audit feeds a refresh queue I work through with the client’s writer, applying the right rule per tier.
PROBLEM 3 · CANNIBALIZATION
22 article pairs splitting their own clicks. The merge-vs-differentiate rule is the difference between a recovery and a regression.
🩺 THE SYMPTOM
Two articles on your blog cover the same intent under slightly different titles. Both rank on page 2. Both get ~50 clicks a month. Combined they would rank on page 1 and earn 500. Google cannot decide which one to surface and oscillates between them, never giving either enough authority to break through. The blog calendar keeps adding adjacent posts, multiplying the problem.
🔍 The diagnosis path I use
Cannibalization detection is unreliable when you look only at keyword overlap, synonyms and longtail variation hide a lot. The cleaner signal is SERP overlap: do the two articles trigger the same set of result URLs from Google for their target queries? Google’s own guidance on consolidating duplicate URLs emphasizes canonicalization plus 301 redirection as the recommended path when two pages compete for the same intent. I score this with Jaccard similarity on the top-10 SERP for each article’s primary keyword:
- J = 1.0, identical SERP, identical intent. Pure cannibalization.
- J ≥ 0.8, strong overlap. Almost certain cannibalization.
- J 0.4–0.8, partial overlap. Differentiation possible.
- J < 0.4, distinct intent despite keyword overlap. Leave both.
For ND, 22 pairs scored ≥ 0.4. The highest-Jaccard pair was “15 Best Christmas Nail Art Ideas” vs “15 Best Christmas Nail Colors”, Jaccard 1.0 across the entire top-10 SERP. By the rule alone, this is a MERGE candidate.
This is where the rule needs a human gate. Read the two titles as a nail-supply operator and the intents pull apart: “Art Ideas” is about designs (snowflake patterns, reindeer art, candy cane motifs), the reader is looking for visual inspiration. “Colors” is about palettes (red/green/gold pairings, dusty rose alternatives), the reader is looking for shade combinations. The SERPs overlap because both compete inside the same Christmas-nail topical cluster, but the user intent is genuinely distinct. Merging the two would force one half of the audience onto a page that does not answer their question.
This is exactly the case the audit pipeline cannot decide alone. The Jaccard score earns the pair a flag; the operator’s domain knowledge decides whether to MERGE or DIFFERENTIATE. For this pair the call is DIFFERENTIATE: sharpen each title to reflect its actual angle, rewrite the intros so intent is unambiguous in the first paragraph, and cross-link them as related-but-distinct reads in the same cluster.
🛠️ The fix rule by Jaccard tier
The 404 same-brand rule matters because cannibalization merges often surface broken internal links to old slugs along the way. When you fix those broken links, search for the same brand’s current collection first before falling back to a generic destination. Brand catalogs survive slug changes; categories do not. Defaulting to /collections/all is the lazy fix that destroys topical relevance.
📊 The result at ND
- 22 pairs scored by Jaccard, then filtered through intent review: 6 confirmed MERGE, 13 DIFFERENTIATE, 3 KEEP BOTH
- Christmas pair: J=1.0 by the rule, but intent review reclassified to DIFFERENTIATE, Art Ideas (designs) vs Colors (palettes) are distinct user questions inside the same topical cluster
- Why the human gate matters: 2 pairs that scored MERGE-tier on Jaccard would have lost half their audience if merged blindly. The audit pipeline flags candidates; the operator’s domain knowledge decides the action.
- Expected lift (industry benchmark): cleanly merged cannibal pairs typically recover 60–90% of combined pre-merge traffic within 8–12 weeks. Cleanly differentiated pairs typically recover 30–50% over a longer window once intent signals stabilize.
📌 WHAT YOU CAN DO YOURSELF
Pick the 10 top-impression queries from GSC. For each, search Google in incognito. If two of your own articles appear in the top 10 results, that is a candidate pair. Read both titles like a customer of your category. If they answer the same question, merge the weaker into the stronger with a 301. If they answer adjacent questions inside the same topic, differentiate the titles + intros and cross-link. Jaccard tells you what to LOOK at; intent tells you what to DO.
The Jaccard rule is a flagger, not a decider. Skip the human gate and you will merge pairs that should have stayed apart, and lose half the audience you were trying to consolidate.
PROBLEM 4 · SOURCING + E-E-A-T
194 of 309 articles had zero external links. AI search treats your blog like an island.
🩺 THE SYMPTOM
Your articles cite no outside sources. The factual claims sit unverified inside the body. AI engines (ChatGPT, Perplexity, AI Overviews) treat content that does not cite authority as one-sided opinion, never extract passages from it, and reflect that back to Google as a weak E-E-A-T signal. Even your factually correct articles get the “no citations, low trust” treatment.
🔍 The diagnosis path I use
I count outbound links per article and stratify by source tier:
- Tier 1: government (.gov), academic (.edu), official brand sites, scientific journals, FDA/EPA/CDC equivalents. Highest authority. AI engines preferentially extract from these.
- Tier 2: established trade publications, Wikipedia (for definitions), well-known industry blogs with byline authors and editorial oversight.
- Tier 3 (avoid): low-quality blogs, anonymous content sites, direct-competitor stores. Linking down-tier costs more than it earns.
For ND the audit revealed 194/309 articles (62.8%) with zero external links. Of the 115 that did cite, the majority cited a single Wikipedia link or a single trade blog. Almost none cited a Tier 1 source. This is the single biggest E-E-A-T lever a content audit can identify, because it is fixable per-article in 15–20 minutes of editorial review.
🛠️ The fix rules I apply
The two-gate system is the discipline I run on every refreshed article. Factcheck without a quality score lets through technically-correct-but-thin content. Quality score without factcheck lets through well-written articles with fabricated stats. Both gates exist for a reason, the failure mode I have seen most in client engagements is the article that “looks great” but cites three sources that 404 or contradict the claim.
📊 The result at ND
- 302 articles flagged for sourcing upgrade (the original 194 with zero links + 108 with only single Tier 3 citations)
- Sourcing baseline established: 2–3 Tier 1/2 outbound minimum, anchor diversity ≥ 3 unique variants per target URL
- Factcheck + Quality Score gates integrated into the refresh workflow, every refreshed article runs through both before going live
- Expected impact: E-E-A-T improvement signals over 3–6 months, AI citation rate measurable via Perplexity/ChatGPT brand mention tracking.
📌 WHAT YOU CAN DO YOURSELF
Pick 10 of your top-traffic articles. Count the outbound links. If most have zero or one, you have the same gap as 62.8% of ND’s blog. Add 2–3 Tier 1 or Tier 2 sources per article, placed at the claim. The 20 minutes per article you spend on this is the highest-ROI editorial work you can do, it improves E-E-A-T, improves AI citation eligibility, and signals to Google that you are part of a knowledge graph, not an island.
In a sprint, every refresh runs both gates. In an audit, the priority list is delivered with sources pre-suggested.
FREQUENTLY ASKED
Common questions about the blog audit pipeline
How do I audit 309 articles without spending a month?
Parallelize the per-article work and reserve the human review for cross-article patterns. A pipeline can crawl every URL, score schema completeness, pull GSC impressions and click trends, count outbound links, and compute decay signals in parallel. The 2-day timeline assumes a streaming setup where article scoring runs concurrently with API rate limits. The cross-article work, cannibalization mapping, cluster authority, link reciprocity, is the part that still benefits from operator review because rules alone misclassify intent.
Why is “0 impressions” a rewrite signal instead of “add FAQ”?
An article with zero GSC impressions for an entire year is not impression-deficient because of structural gaps; it is impression-deficient because Google has decided it does not match useful intent. Adding a FAQPage schema does not change the underlying intent mismatch. The article needs a real content rewrite that re-targets the keyword cluster, plus a publishDate update to today to signal re-crawl. FAQ schema is the right fix for an article that is ranking but not earning rich-result eligibility, not for an article that is invisible.
When should I MERGE cannibalizing pairs vs DIFFERENTIATE them?
Jaccard scores you the SERP overlap; intent review decides the action. If the two articles answer the same question (e.g. “best gel polish for beginners” written twice), MERGE by picking the canonical winner by traffic, redirecting the loser, and lifting the loser’s unique paragraphs into the canonical. If the two articles answer adjacent but distinct questions inside the same topical cluster (the Christmas Art vs Colors case in this audit), DIFFERENTIATE by sharpening titles, rewriting intros so intent is unambiguous, and cross-linking as related reads. A J=1.0 score does not auto-mean MERGE.
How do I add JSON-LD schema to a Shopify blog at scale?
Schema is a template-level fix, not per-article. Edit the theme’s article.liquid template once, emit a JSON-LD block in the head, and pull the per-article values (headline, author, datePublished, dateModified, image) from Liquid variables. The FAQPage block is extracted from H2 patterns ending with “?” plus the first following paragraph; skip the schema on articles with fewer than two qualifying H2s to avoid thin FAQPage penalties. The result is one template change that covers every existing article and every future one.
What is the difference between the audit and the 90-day sprint?
The 7-day Audit produces the diagnosis, the prioritized queue, and the decision rules as a PDF + Loom walkthrough you can implement yourself. The 90-day Sprint includes the audit plus 90 days of hands-on execution: schema template ship in week 1, refresh queue worked through with the in-house writer, cannibalization merges executed with redirects, sourcing baseline upgraded across the priority articles. You get the deliverable either way; the Sprint adds the implementation hours so the audit findings actually land in production.
WHAT THIS CASE DEMONSTRATES
The skills behind a portfolio-scale audit
🔬
Portfolio-scale audit with parallel scanners
309 articles processed in 2 days. Per-article quality + decay + schema scoring, then cross-article cannibalization and cluster authority graphs. Pipeline, not eyeball.
📐
Decision rule frameworks per category
Refresh tier by impression count. Merge tier by Jaccard. Sourcing tier by source authority. Rules survive when the operator does not.
🏗️
Schema engineering at portfolio scale
Template-level JSON-LD generation, FAQPage extraction from H2 patterns, Schema.org validation. One template, 309 articles fixed.
🤖
AI citation readiness (GEO)
Answer-first formatting, tier-1 sourcing baseline, Schema.org coverage. The full ChatGPT / Perplexity / AI Overview stack, not just Google.
Your blog has more articles than you can audit by hand
If you have 50+ articles, the math is against the eyeball method. The 7-day Audit produces the prioritized queue, the decision rules, and the refresh roadmap. Sprint engagements ship the schema patch + execute the queue.